The Subtraction Principle: Why Harness Engineering Matters More Than Your LLM

Writer
Quiz available
Take a quick quiz for this article.
For the last year, the AI engineering community has been obsessed with a single question: Which model is the best?
Recent research from Stanford and Tsinghua University definitively proves that we have been asking the wrong question entirely. The orchestration code wrapping your LLM now drives more performance variation than the model itself. In fact, depending entirely on the wrapper—or “harness”—built around it, you can observe a 6x performance gap using the exact same frontier model.
Welcome to the discipline of Harness Engineering. If you are building AI agents today, the reusable, high-value asset is no longer the LLM you choose to plug in. It is the architecture you build around it.
Mature harness engineering looks less like building structure up, and more like aggressively pruning it down. The competitive moat is now the harness.
The Operating System Analogy
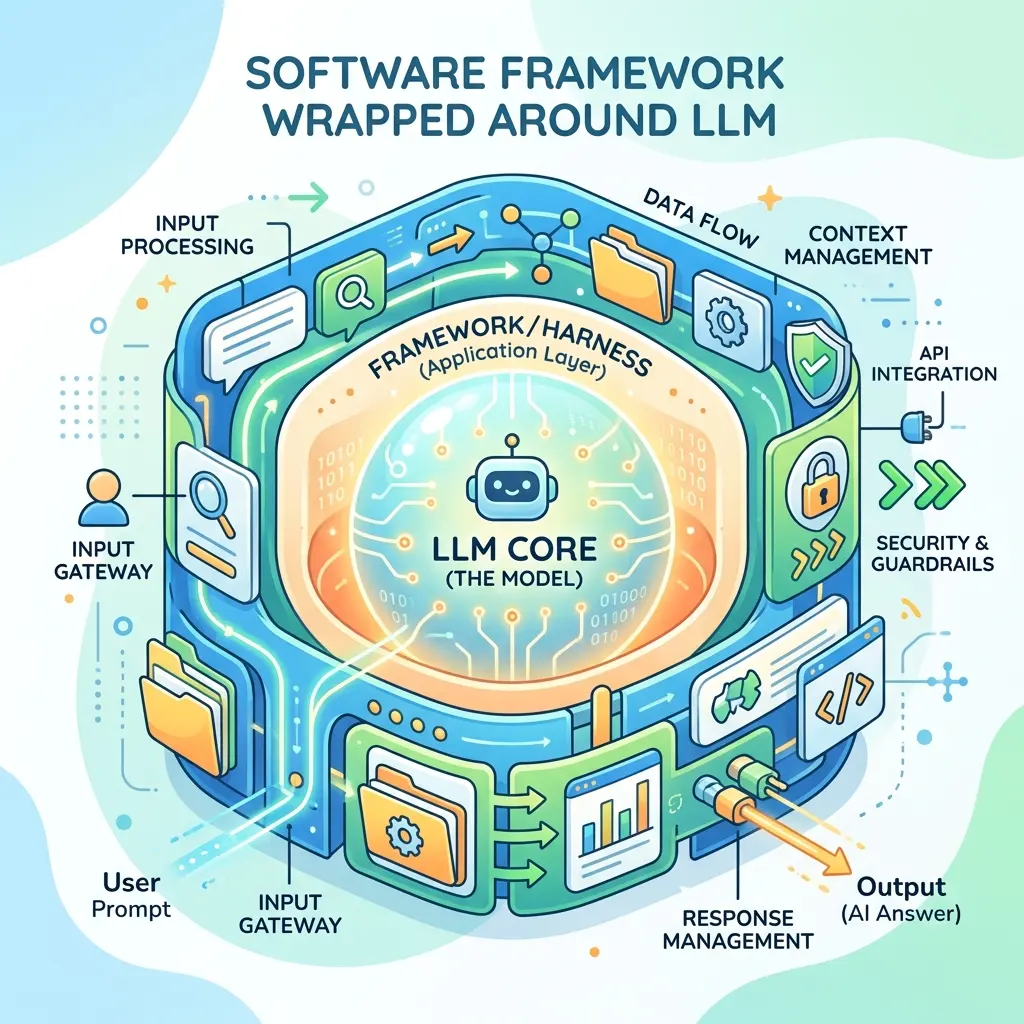
To understand why the harness is the primary bottleneck for agentic performance, we have to clearly define what a harness actually is. In simple terms, it is the architecture that turns a stateless, one-shot text generator into a persistent agent capable of taking actions, observing consequences, and driving toward a goal.
The cleanest way to map this is through an operating system analogy:
- Raw LLM: The CPU. It is incredibly powerful but entirely inert on its own—it has no memory, storage, or I/O.
- Context Window: The RAM. It is fast, highly accessible, but strictly limited.
- External Databases: Act as the hard disk.
- Tool Integrations: Serve as the device drivers.
The Harness is the Operating System. It is the control logic deciding exactly what the CPU sees, when it sees it, and how it persists state.
Understanding this separation of concerns is critical. The same “CPU” will perform vastly differently depending on the efficiency of the “OS” routing tasks to it.
Insight 1: Representation Matters (The Tsinghua Findings)
A landmark paper from Tsinghua University (March 2026) fundamentally challenges how we write control logic. The researchers asked a provocative question: What if an agent’s control logic was written entirely in structured natural language instead of Python or YAML?
They separated the architecture into three distinct layers:
- Backend: The physical infrastructure and tools.
- Runtime Charter: The “universal physics” of the system—how contracts bind, how state persists, and how child agents are managed.
- Natural Language Harness: The state-specific logic, including roles, contracts, and failure modes.
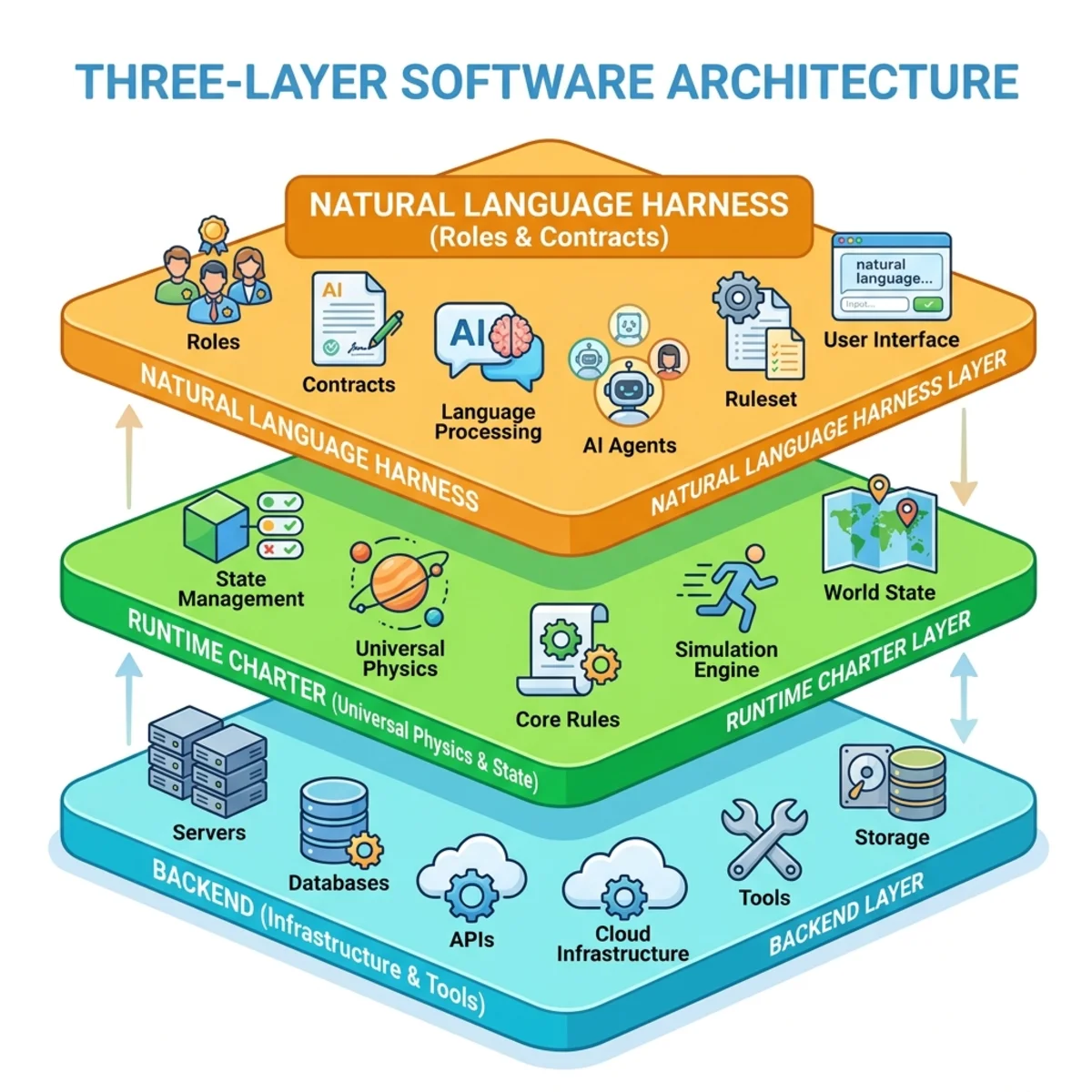
By isolating the harness in natural language, they achieved controlled experimentation. The results were staggering. When they migrated the OS Symphony desktop automation harness from native code to a natural language representation, performance jumped from 30.4% to 47.2%.
More importantly, efficiency skyrocketed. Runtime collapsed from 361 minutes to 41 minutes, and LLM calls plummeted from 1,200 down to just 34. The representation of the logic alone drove the gain.
Pro Tip: Moving your agent’s control logic from rigid code (Python/YAML) into structured natural language significantly reduces token spend and execution time.
Insight 2: The Cost of Complexity and the “Subtraction Principle”
The AI industry has spent the last year bolting more and more tools, verifiers, and search loops onto agents in an attempt to make them smarter. The data shows this is actively harming performance.
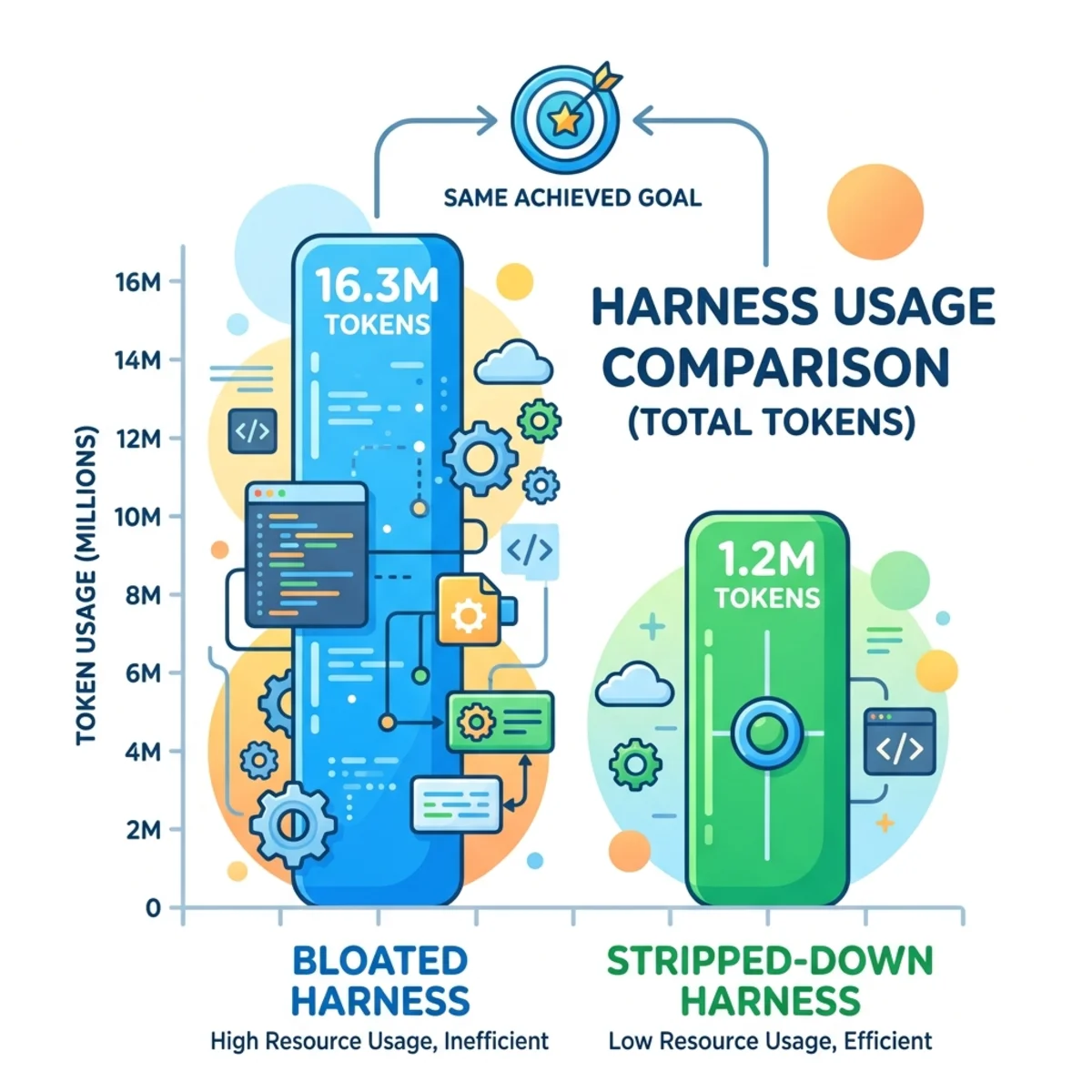
During ablation studies on SWE-bench, Tsinghua researchers found that while a bloated harness burned through 16.3 million tokens (over 600 tool calls and 32 minutes of runtime) to achieve a ~75% success rate, a heavily stripped-down version achieved the exact same result using only 1.2 million tokens. That is 14x less compute for the same destination.
Counter-intuitively, more structure is not better:
- Verifiers actually degraded performance (-0.8 on SWE-bench, -8.4 on OSWorld).
- Multi-candidate search hurt scores by 5.6 points.
- Only self-evolution consistently helped.
This introduces what Anthropic calls the Subtraction Principle. Every component you add to a harness encodes an assumption about what the model cannot do alone. As frontier models natively improve, those assumptions expire. Your legacy scaffolding becomes a cognitive burden on the model.
Industry leaders are already adapting to this:
- Anthropic recently dropped context resets entirely for Opus.
- Manis rewrote their harness 5 times in 6 months.
- Vercel removed 80% of their agent tools and saw an immediate increase in performance.
Insight 3: Auto-Optimizing Harnesses (The Stanford / DSPy Findings)
If representation and subtraction are the keys to performance, how do we find the perfect harness? A paper from Omar Khattab (creator of DSPy) at Stanford proposes an automated solution.
They built an agentic proposal loop where an LLM (e.g., Claude Opus) reads failed execution traces, diagnoses the breakdown, and autonomously rewrites a new harness. Operating at a scale of 10 million tokens and ~82 files read per iteration, the system proved that raw data is irreplaceable.
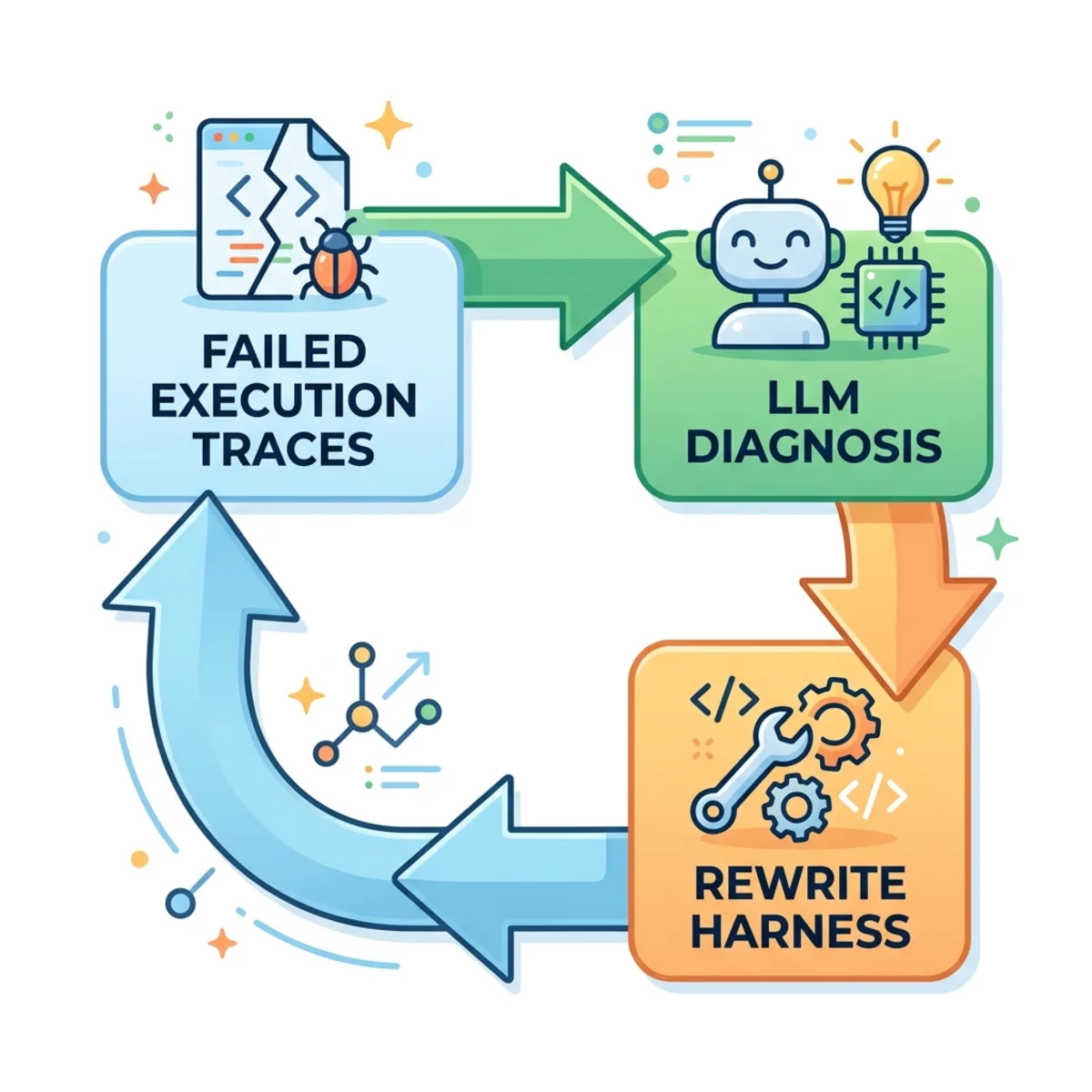
Crucial Gotcha: When researchers tried to save tokens by feeding the optimization loop AI summaries of past failures instead of raw execution traces, accuracy tanked from 50% down to 34.9%. The actionable signal lives strictly in the raw details.
The most profound finding from this experiment? Transferability. A harness automatically optimized for one model successfully transferred to five completely different models, improving the performance of all of them. Through harness optimization alone, smaller models (like Haiku) were able to outrank larger frontier models (like Opus). The harness is the reusable asset, not the model.
Real-World Application: The IDE Test
If you pass a complex prompt to the exact same model inside different IDEs—Cursor vs. Claude Code vs. Windsurf/Void—you will see entirely different reasoning paths, token spends, and success rates. The model isn’t failing you; your harness is.
The Actionable Debugging Checklist
If you are building an agent today, you are a harness engineer. When your agent underperforms, do not immediately swap out the LLM. Instead, audit your OS. Run through this four-step checklist:
- Audit the RAM: What is currently in your context window that does not strictly need to be there? Remove it.
- Prune the Drivers: Look at your tool integrations. Which tools does the agent rarely or incorrectly use? Delete them.
- Kill the Bloat: Are you forcing verification loops or multi-candidate searches? Test removing them; they might be actively degrading your success rate.
- Refactor the OS: Is your control logic heavily reliant on rigid Python/YAML code? Try migrating that exact logic into structured natural language.
We are no longer in an era where picking the best model guarantees the best product. The competitive moat is now the harness. Keep it natural, keep it raw, and most importantly—keep it simple.
Read next


